Tic Tac Toe
In this tutorial, we will train an agent to play Tic Tac Toe by using Temporal Difference learning. This tutorial can be used as a supplementary material for the book "Reinforcement Learning: An Introduction" (Sutton, Barto) - Chapter 1. Specifically, the agent is trained with an opponent, who plays randomly. A self-play strategy can be implemented in a similar way.
Although Tic Tac Toe (3x3) is quite simple, its state space is reasonably large. The information of Tic Tac Toe can be found here: "A simple upper bound for the size of the state space is 3^9 = 19,683. (There are three states for each cell and nine cells.) This count includes many illegal positions, such as a position with five crosses and no noughts, or a position in which both players have a row of three. A more careful count, removing these illegal positions, gives 5,478. And when rotations and reflections of positions are considered identical, there are only 765 essentially different positions. A simple upper bound for the size of the game tree is 9! = 362,880. (There are nine positions for the first move, eight for the second, and so on.) This includes illegal games that continue after one side has won. A more careful count gives 255,168 possible games. When rotations and reflections of positions are considered the same, there are only 26,830 possible games."
To make the program extendable, it is essential to create a dynamic state-value table. We include all possible states of the environment when using a static table. In contrast, a new state is only added to the dynamic table while the agent is in training. In Python, a dictionary can be used as a dynamic state-value table. One square of the board can be in three states: empty (0), nought (1), or cross (2), denoted as a(j), where a(j) = {1, 2, 3} and j is the index of j-th square in the board. Therefore, a state of a board can be calculated as below:
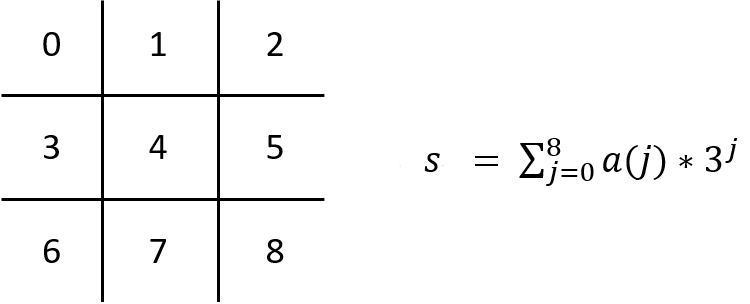
The agent is trained with a "random player". Each step of the agent is selected based on the Epsilon-Greedy strategy. The state-value table is updated in every step. As a reminder, the old state-value is replaced with the new one by using the following update rule:
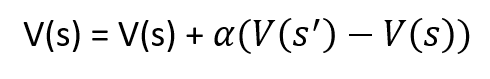
The source code can be found here https://github.com/garlicdevs/Fruit-API/blob/master/fruit/samples/rl_basics/chapter_1.py
Contact us at
hello@fruitlab.orgor join our community athttps://www.facebook.com/groups/fruitlab/to post any questions.